Voordeel van
een vectorieel beeld is dat het gemakkelijk kan vergroot of verkleind worden omdat enkele de waarden in de formules moeten
aangepast worden. Daarenboven moet slechts heel weinig informatie worden opgeslagen zodat deze files zeer klein zijn.
Een bitmapbeeld
daarentegen zal bij uitvergroten randen vertonen (een trap-patroon). Men noemt dit verschijnen van pixels (puntjes) de “pixelisatie”
of “aliasing”. Een vectorbeeld vergroten of verkleinen geeft dus geen verlies aan informatie, een bitmapbeeld
verliest wel aan informatie wanneer het gewijzigd wordt (de zgn “distorsie”).
Nadeel van een vectorieel
beeld is dat het niet zeer complex kan zijn omdat alles in wiskundige formules moet kunnen vastgelegd worden en dit is bij
een beeld met veel nuances of vormen erg complex. Men kan eventueel verschillende vormen op elkaar leggen in “layers”
en aldus complexe beelden maken, maar een realistische foto is en blijft te complex om opgeslagen te worden als vectorbeeld.
Gescande beelden zijn dus altijd bitmaps. Dit verklaart waarom een vergroting van een gescand beeld steeds hoekinger wordt
naargelang het uitvergroot wordt op scherm.
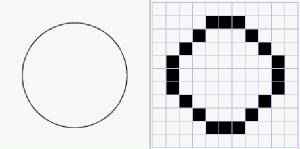
In de bitmap hierboven
kunnen we onze “blokjes” of “pixels” groter of kleiner kiezen. Hoe kleiner de pixels, hoe fijner het
beeld is, hoe meer detail kan getoond worden. Nadeel is dat er meer “pixels” opgeslagen moeten worden en de file
dus meer plaats zal innemen op de harde schijf waarop hij bewaard wordt.
Bij het vertonen van
een beeld geldt hetzelfde. Een scherm met een “hoge resolutie” (vb 1152x864) zal een minder hoekig beeld geven
dan een scherm op “lage resolutie” (vb 840x480) omdat de puntjes op het eerste scherm veel kleiner zijn dan op
het tweede. Hetzelfde geldt voor een afdruk : hoe meer puntjes de printer afdrukt per cm hoe fijner het gedrukte beeld.
Deze “fijnheid”
wordt uitgedrukt in DPI (“dots per inch” = aantal puntjes per 2,54 cm). Hoe hoger dit getal, hoe fijner het beeld,
maar hoe meer plaats nodig is voor opslag.
Deze fijnheid speelt
een rol zowel bij opslag (scanning) als bij weergave en de fijnheid bij weergave kan nooit hoger zijn dan de fijnheid bij
scanning. Het is dus onmogelijk een beeld dat “grof gescand” is te verfijnen. Het heeft geen zin te proberen een
beeld “duidelijker te maken” door het af te drukken op 400 DPI als
het maar gescand werd op 200 DPI bv.
Anderzijds is het
zo dat een scherm met een resolutie van 72 DPI al een redelijk goed resultaat geeft. Een printer met een soortgelijke resolutie
wordt aanzien als erg grof. Daar wordt meestal toch minstens 300DPI als resolutie gebruikt. Gevolg is dat een afgedrukt beeld
veel genuanceerder is dan een beeld dat op scherm wordt vertoond.
Kleurnuances
Daarenboven heeft
elk scherm ook zijn eigen specifiek “kleurpatroon”. Het kleurenspectrum dat een afficheringstoestel (scherm, drukker,
…) kan laten zien heet “gamut”. De kleuren die niet kunnen geafficheerd of afgedrukt worden heten “buiten gamma”.
In de grafische industrie
speelt deze “gamut” een grote rol omdat kleurechtheid daar zeer belangrijk is : de kleur van de scanner of het
scherm wil men immers zo getrouw mogelijk terugvinden op papier. Voor ons is dit van minder belang maar we moeten ons wel
bewust zijn dat de kleur van de oorspronkelijke foto, die van het scherm en die van een eventuele afdruk erg kunnen verschillen.
Het is onrealistisch in een gewone bureelomgeving te verwachten dat de kleuren voor deze 3 bronnen perfect gelijkend zouden
zijn. Zowel scanner als printer als scherm hebben immers een hoop kleuren “buiten gamma”.
Hetzelfde geldt ook
voor afdruk natuurlijk. Een drukpers kan nu eenmaal veel meer kleurnuances afdrukken dan een gewone printer. De “gamut”
van de pers waarop een kunstboek wordt gedrukt is dan ook veel groter dan die van de printer op een bureel.
Vergeet ook niet dat
iedereen een eigen visie heeft op kleur. Geen 2 mensen nemen eenzelfde kleur op dezelfde manier waar. Ook dit speelt een rol
bij de beoordeling van de “kleurechtheid” van een gescand document.
Gezien de verschillende
media (scanner, scherm, printer, …) allemaal hun eigen specifieke “kleur-eigenschappen” hebben maar we toch
de kleuren die we met 1 ervan hebben verkregen graag ook zo dicht mogelijk door de andere willen benaderd zien, moeten we
printer, scanner en scherm zo goed mogelijk op elkaar afstellen. Dit noemt men de “calibrage”. We gaan hier niet
verder op in omdat dergelijke callibrage enorm complex is.
De enige “kleurbalansen”
die gebruikt worden zijn de verschillende instellingen op de scanner zelf. Het gaat hem dan om voorafgeprogrammeerde balansen
van kleur en belichting die functie zijn van de eigenschappen van het oorspronkelijke documenttype.
Kleuropslag
Hiermee zijn we aangeland
bij kleurscanning. Er zijn oneindig veel kleurschakeringen en een ge-oefend menselijk oog kan er 2 miljoen onderscheiden,
het heeft geen zin om tot in het oneinidige te proberen om deze ook allemaal vast te leggen bij scanning. Ook hier weer moet
een balans gemaakt worden tussen enerzijds het volume van de file en anderzijds de getrouwe overeenkomst van het gescande
beeld met het oorspronkelijke document.
Een computer kent
maar 2 waarden voor een bepaald gegeven : het is waar of het is niet waar. Men stelt dit voor als resp “1” en
“0”. Eén enkele “aan/uit” noemt men een “bit”.
Eén bit heeft natuurlijk
niet de mogelijkheid veel informatie te bevatten en om een gegeven op te slaan (bv het cijfer 3) kom je dus met 1 “aan/uit”
niet toe. Daarom worden 8 bits samengenomen in een zgn “byte”. Door aan elke mogelijke combinatie van nulletjes
en ééntjes die elkaar binnen een byte opvolgen een andere betekenis toe te kennen krijgt men al 256 verschilende mogelijkheden. Genoeg om een volledig alfabet samen te stellen en nog plaats over te houden voor “speciale
tekens”. Welke waarde aan welke opeenvolging wordt gegeven vindt men terug in zgn “code-tabellen”. Bekendste
zijn de ASCI (vooral op PC) en de EBCDIC (vooral op grote computers).
Om een beeld
op te slaan is men natuurlijk niets met deze codetabel, maar men kan aan de inhoud van zo’n bit of byte elke betekenis
toekennen die men maar wil. Zo kunnen we bv zeggen “als de bit = 1 is de pixel wit, als hij = 0 dan is de pixel zwart”.
We hebben dan de mogelijkheid om een beeld in zwart/wit vast te leggen en dit neemt erg weinig plaats in : 1 bit per pixel (puntje). In 1 byte kunnen we dan 8 puntjes van het beeld vastleggen.
Wanneer in 2
kleuren wordt gewerkt (zwart/wit) volstaat 1 “bit” per pixel. Het puntje kan zwart zijn of wit. Maar men kan ook
een volledige byte gebruiken voor 1 pixel. In dat geval kan men aan elke mogelijke opeenvolging van bits binnen de byte de
betekenis toekennen van een grijswaarde. Men heeft dan 256 nuances “grijs” ter beschikking tussen zwart en wit.
We kunnen nu nog verder
gaan. Waarom niet 3 bytes combineren en aan elke ervan een nuance toekennen van de 3 hoofdkleuren (rood, groen en blauw) ?
De eerste byte van de combinatie zegt hoeveel “rood” de pixel bevat, de tweede byte hoeveel groen en de derde
hoeveel blauw. We hebben nu dus 24 bits nodig per pixel, maar kunnen er 256 x 256 x 256 kleuren mee uitdrukken (16 777 216
verschillende nuances, dus meer dan het menselijk oog aankan). Dit volstaat ruimschoots voor een zeer genuanceerd kleurpalet.
Met 2 bytes halen we nog 32768 nuances, ruimschoots voldoende voor een goede technische kleurenscan. Vergeten we ook niet
dat het nutteloos is om in 24bit te scannen als de “gamut” van het scherm te beperkt is om zoveel kleuren te afficheren
(meestal stelt men zijn scherm in op 32768 of 65536 kleuren).
Er bestaan nog andere
mogelijkheden om kleuren samen te stellen (HSB, CYMK, …) en vast te leggen, maar in principe is de basis steeds dezelfde.
Hier verder op ingaan gaat het doel van deze instructieset tebuiten, maar het principe blijft geldig dat “hoe meer kleuren,
hoe meer nuances er zijn, hoe meer plaats men nodig heeft om 1 enkel puntje van het beeld vast te leggen”.
Vermits 1 puntje al
zoveel plaats inneemt, wat moet dan geen ganse foto zijn ? De opslagruimte hiervan kan inderdaad zwaar oplopen. Maar een foto
heeft vaak grote delen die alemaal dezelfde eigenschappen hebben. Wanneer op een foto van een schilderij bv een blauwe rechthoek
staat dan hoeft die niet noodzakelijk puntje per puntje opgeslagen te worden. Er kan een ganse “blauwe vlek” opgeslagen
worden door slechts 1 maal de kleur te beschrijven en dan van waar tot waar deze loopt.
Hierdoor wordt de
file (de benodigde opslagruimte) al veel kleiner. Een beeld op deze manier verkleinen heet “comprimeren” en er
bestaan verschillende “algoritmes” voor, verschillende manieren om het aan te pakken (PackBits, Lempel-Ziv-Welch
(LZW) ,CCITT Fax 3 & 4, …). Elke scanner en scanprogramma geeft de mogelijkheid het beeld te comprimeren voor opslag.
Voor de gebruiker is deze compressie iets waar hij zich dan ook weinig moet van aantrekken, mits hij maar weet welke prijs
hij er eventueel voor moet betalen.
Want er is een “MAAR”.
Er kan gecomprimeerd worden met of zonder kwaliteitsverlies. Kwaliteitsverlies is er bv wanneer 2 of meer naast elkaar liggende
pixels bijna dezelfde kleur hebben. Dan kan het compressieprogramma een kleur kiezen die tussen de beiden inligt en al deze
pixels samen nemen. Hetzelfde kan gebeuren met een klein hoekje in een beeld. Hier kan het programma gewoon dit hoekje wegsnijden
om de opslag van het beeld minder volumineus te maken. Wanneer men later deze foto of dit gescand document dan terug bekijkt
is deze informatie niet meer aanwezig. Ze is definitef verloren en kan nooit meer gerecupereerd worden. Men noemt compressie
met informatieverlies “lossy compression”.
Vaak zal kleur gemakkelijker
te comprimeren zijn dan grijswaarden en een grijsbeeld kan op schijf dan ook groter zijn dan een kleurbeeld van dezelfde afmetingen.
Archiveer daarom best geen
gecomprimeerde digitale documenten!
· decompressie
is een extra reconstructieschakel die botst met het principe om afhankelijkheden zoveel mogelijk te vermijden
· bij
lossy compressie gaat informatie en kwaliteit verloren. Voor audio-visuele archiefdocumenten wordt het kwaliteitsverlies,
de ruis en/of de vervormingen gemakkelijk auditief of visueel waarneembaar wanneer verschillende opeenvolgende compressie-algoritmes
worden toegepast
· het
verwerken van gecomprimeerde bitstreams (opeenvolging van bits) is complexer
· gecomprimeerde
digitale documenten zijn kwetsbaarder dan ongecomprimeerde documenten. Een fout in een gecomprimeerd bestand leidt sneller
tot onherstelbaar verlies
· de
compressienoodzaak vloeit meestal voort uit technologische beperkingen (verwerking, opslag, transmissie). Deze restricties
zullen ten gevolge van de technologische vooruitgang de komende jaren soepeler worden of zelfs helemaal verdwijnen.
Als compressie onvermijdelijk
is, opteer dan voor een lossless compressiemethode (zonder informatieverlies) en
kies een compressie met een open, gedocumenteerd en gestandaardiseerd decompressie-algoritme.
Een beeld kan, net zoals elk ander bestand,
op verschillende manieren worden opgeslagen. De opslag kan verschillende “regels” volgen. Een van deze regels
zegt bv op welke manier het aantal gebruikte kleuren wordt opgeslagen, of welke compressie-algoritme gebruikt is (vb GIF gebruikt
altijd LZW, …). Zo’n regels die de opslag beschrijven noemen we een “file-formaat” (TIFF, GIF, BMP,
JPEG, …).
Wanneer we weten in welk “formaat”
een beeld is opgeslagen weten we dus automatisch hoe we het terug zichtbaar kunnen maken. We weten dan immers welke regels
de “viewer” moet
gebruiken om de lijst van nulletjes en ééntjes terug om te zetten in een zichtbaar beeld.
Gezien elk formaat zijn eigen regels heeft
die elk wel ergens voor- en nadelen hebben hangt het af van het doel van de opslag om te weten welk formaat best gekozen wordt.
Eén van de belangrijkste factoren die meespelen is de vraag waar men het meeste belang aan hecht : de opslagruimte of de waarheidsgetrouwheid
van het beeld.
Zo is bv TIFF een formaat dat als voordeel
heeft dat er bij compressie geen informatie verloren gaat, maar het heeft als nadeel dat zelfs na compressie de file erg groot
blijft. Aan de andere zijde van het spectrum staat het erg populaire JPEG dat een massa informatie verliest maar anderzijds
enorm compact is en dan ook hét formaat bij uitstek is voor electronische foto-camera’s
en voor foto-uitwisseling op INTERNET.