OCR
DEFINITIE
Wanneer men een document scant dan vertaalt de scanner wat hij
ziet in een digitaal beeld en zendt dit naar de computer. Dat is interressant voor de meeste documenten maar volstaat niet
als men daarna de tekst nog wil gebruiken om op verder te werken. Om dit te verhelpen werd “OCR” uitgevonden.
OCR (= Optical Caracter Recognition) is een applicatie die tekens in een (gescand) beeld interpreteert en omzet in voor computerprogramma’s
verstaanbare taal. “Bitmap-foto’s” van “letters” worden dus via herkenning van lichte en donkere
patronen omgezet in “computercodes”. Gesofisticeerde systemen gebruiken hiertoe een combinatie van hardware (speciale
circuit-kaarten) en software. Daarenboven bevatten ze vaak woordenboeken (en voor gesofisticeerde systemen zelfs gramatica’s)
waarin het systeem het meest waarschijnlijke woord kan opzoeken wanneer het ergens twijfel heeft maar toch het merendeel van
de letters met grote zekerheid heeft kunnen ontcijferen.
Door OCR'en neemt een A4-pagina met tekst
nog maar een paar kilobyte aan geheugenopslag in. Belangrijkste voordeel van OCR is echter dat de tekst wordt omgezet in code
(vb ASCII), wat toelaat erin te zoeken (vb naar een bepaald woord) of er bewerkingen op te doen (bv in een tekstverwerker).
Probleem vroeger was dat er in de drukwereld
verschillende lettertypes (“fonts”) bestaan. Zo heeft een eenvoudige karakterset als “Roman” niet
hetzelfde uitzicht als een meer “kunstzinnige”, heb je schreefhoudende en schreefloze fonts (er staan al dan niet
streepjes aan de letters). Daarnaast worden titels over het algemeen ook groter afgedrukt dan platte tekst. OCR moet in staat
zijn zoveel mogelijk van deze fonts te ontcijferen, in welke afmeting of welk lettertype ze ook gedrukt zijn.
De afbeelding wordt met een resolutie van 200-400 dpi (meestal in zwart-wit) gescand en geanalyseerd op herkenbare tekens.
Tegenwoordig worden de meeste karaktertekens van het latijnse schrift zonder veel fouten ingelezen (98% correct).
Sommige OCR-systemen slagen er nu zelfs
al in de bladspiegel te reproduceren zodat ook foto’s en tabellen worden omgezet, eventueel zelfs in kolommen. Sommige
applicaties staan toe het “te vertalen” stuk te beperken tot een deel van het beeld. Bijna allen kunnen ze verschillende
lettergrootten , Bold en Underline aan, Italic is iets zeldzamer maar verbetert bij iedere versie. Hierdoor zijn titels en
ondertitels meestal wel als zodanig ook in de omgezette tekst aanwezig.
Omdat OCR (OMR en zeker ICR) zo moeilijk
zijn wordt in zeer performante systemen de techniek van “Tandem Voting” toegepast. Soms wordt de ganse tekst,
soms enkel de twijfeltekens, door 2, 3 of meer verschillende OCR-aplicaties gelezen ofwel meermaals door dezelfde. Telkens
wordt beslist hoeveel kans elke lezing geeft dat zijn interpretatie juist is. Dan worden deze kansen vergeleken en de meest
waarschijnlijke uitgekozen. De correcte lezeing verhoogt hierdoor met zowat 50% verhoogd.
EISEN
Sommige documenten zijn dan ook gemakkelijker te interpreteren dan
andere. Hoewel de OCR-software steeds performanter wordt en dus steeds meer “moeilijke” teksten aankan, toch blijft
het aan te raden zoveel mogelijk rekening te houden met het feit dat OCR het best werkt met :
-
Propere originelen
of zeer duidelijke copies (geen copie van een copie van…. , geen verfrommeld papier en geen vlekken)
-
“Mono-spaced fonts” (vb Courier).
-
Letters
van minstens 12 point groot
-
Zwarte tekst
op witte achtergrond. Pas daarom de color/contrast/brightness aan zodat de achtergrond zo licht mogelijk is en vrij van “artifacten”
(d.w.z. patronen in of op het papier)
-
Standaard lettertypes (Times, New Roman, etc.). Kunstzinnige lettertypes (“fonts”)
worden vaak niet gelezen
-
Tekst in 1
kolom
-
Een propere
scanner. Een glasplaat die vuil is geeft een onduidelijker en vaak gevlekt beeld.
-
Rechte tekst.
Wanneer het blad schuin werd afgedrukt of wordt gescand dan heeft OCR er meer problemen mee
-
Hoe complexer
de lay-out, hoe moeilijker te interpreteren, hoewel deze factor steeds minder een rol speelt omdat de OCR-software steeds
sterker wordt.
BEPERKINGEN
-
Te complexe lay-out
-
De tekstfile
moet steeds nagelezen worden op spel- en grammaticafouten. Ook de lay-out moet soms bijgewerkt worden.
-
Formulieren geven vaak veel problemen omwille van de kaders
en aankruisvakjes waar OCR geen blijf mee weet
-
Kleine lettertypes
of Italic
-
Wiskundige formules
-
Kunstzinnige tekst
of lay-out
-
Andere alfabetten dan
het Latijnse of het Cyrillische geven vaak meer leesfouten
STADIA
VAN OCR
Er zijn verschillende fases die doorlopen
worden om tekst te herkennen:
-
Controle van de orientatie, staat de
tekst op z'n kant of op de kop, dan moet de afbeelding eerst geroteerd worden. Ook als de zaak scheef staat is er soms een
mogelijkheid om dit min of meer recht te zetten. Deze functie heet vaak in het engels skew of de-skew, rechte lijnen lopen dan weer recht in plaats van scheef naar boven of onder.
-
Controle van kolommen. Een normale brief
bestaat over het algemeen uit één kolom of tekstblok. Een krant daarentegen heeft meerdere kolommen. Een OCR-programma kan
dit vaak automatisch herkennen. De volgorde van de tekstblokken en/of kolommen is meestal ook te wijzigen door een soort rangorde
met '123' op de bewerkingsknoppen.
-
Tekst en plaatjes scheiden. De tekst
wordt afgezonderd van de rest, waarbij het formaat van de plaatjes veelal in .BMP of .JPG (vroeger .PCX) wordt weggezet.
-
Bij professioneel OCR'en kan de herkenning
ook nog numeriek of alfa-numeriek gezet worden, zodat dus alleen cijfers of cijfers+letters worden herkend. Vooral numeriek
is prettig als veel boekhoudinformatie in bepaalde velden ge-ocr-ed moet worden.
-
Karakterherkenning. De letters worden
stuk voor stuk geanalyseerd op welk teken is het, welk font, grootte, enz. en dan vergeleken met voorbeelden van letters waarover
het programma beschikt. Soms kan een OCR-programma nieuwe voorbeelden toevoegen (de zogenoemde training optie), zodat later
dezelfde soort letter weer herkend wordt. Vaak worden er ook regels toegepast die beschrijven hoe de taal per lands-aard is
opgebouwd.
-
Controle van de woorden met een een bibliotheek
(library) van alle bestaande woorden, de zogenoemde spelchecker. Helaas is bij OCR de begin-letter vaak de discutabele letter
(denk aan geef, beef, leef, zeef, teef, weef, heeft, enz.). Bij eenvoudige OCR-programma's wordt de woordenlijst (taal afhankelijk!)
vaak weggelaten, wat aanzienlijk in tijd en opslag capaciteit van de harde schijven kan schelen. Intelligente spellcheckers
hebben de eigenschap om tijdens het werken ermee alsmaar te groeien in omvang, wat te beperken is door per categorie of onderwerp
(medisch, technisch, historisch, e.d.) verschillende woordenlijsten aan te leggen.
-
Exporteren. Tot slot kan het resultaat
opgeslagen worden. Daarbij kan vaak gekozen worden in welk formaat en in welke mate de oorspronkelijke opmaak gereconstrueerd moet worden. Zo zal een .Doc of .TXT een andere uitvoer geven dan een
.XLS of .PFD extensie, als je kiest voor tekst of spreadsheet, enz.
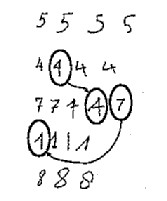
Handgeschreven tekst lezen is vaak al moeilijk
voor mensen gezien de enorme variatie die hier mogelijk is. Een letter of cijfer in een bepaalde font (schrifttekenreeks)
heeft altijd hetzelfde uitzicht maar de manier waarop bv het cijfer 7 wordt geschreven
kan erg verschillen van mens tot mens en vaak lijken op de cijfers 1 of 4 die door iemand anders werden geschreven. Geschreven
tekst “lezen” vraagt dan ook veel achtergrondsdenken en interpreteren. Het heet dan ook niet voor niets ICR (Intelligent
Caracter Recognition).
Om de variatie toch een beetje onder controle
te houden worden voor handgeschreven documenten vaak regels opgelegd die lezing moeten vergemakkelijken. De meest voorkomende
regels zijn :
-
men moet in hoofdletters schrijven : veel uniformer dan kleine letters en nooit aan elkaar geschreven
-
men moet de tekst in vakjes schrijven
: verplicht de mens trager en dus duidelijker te schrijven en heeft het bijkomende voordeel dat het systeem weet waar het
juist moet gaan zoeken op het blad
-
de vakjes worden in een verboden kleur
gedrukt zodat het contrast tussen vakje en tekst duidelijker is : vb rood, een inktkleur die zelden gebruikt wordt om een
document in te vullen.
Een systeem dat voor handgeschreven
documenten 85% juiste lezingen haalt wordt wegens alle ermee verbonden problemen als heel performant aanzien. Dat houdt wel
in dat ongeveer 1 teken op 7 verkeerd wordt gelezen, zodat desondanks toch nog veel manuele verbeteringen nodig zijn.
Toch wordt deze techniek veel en
succesvol ingezet voor het herkennen van handgeschreven teksten op formulieren.
Doordat de tekst daar op vaste plaatsen staat en ook vaak een specifieke betekenis heeft, b.v. postcode, registratienummer,
getal, enz. kan er een “verbetering” gebeuren van verkeerde lezingen en bekomen de software systemen alles bijeen
toch nog een goede herkenbaarheid. Namen daarentegen geven vaak wel problemen omdat daar geen echte regels bestaan voor verbetering.
Adressen zitten tussen beiden in: eens de postcode vastligt kan de straat gemakkelijk “verbeterd worden” aan de
hand van lijsten per postcode, maar dit is wel tijdrovend gezien de enorme massa gegevens waaraan elke lezeng moet getoetst
worden.
Niet alle gegevens worden geschreven of
in vloeiende tekst gedrukt. Zo kan men bv informatie meegeven onder vorm van barcodes. Ook worden op formulieren vaak aankruisvakjes
gebruikt. Ook deze kunnen automatisch verwerkt worden. Hiervoor gebruikt men
OMR (Optical Mark Recognition). OMR herkent allerlei soorten “markeringen” zoals bv het wel of niet ingevuld,
aangekruist of aangevinkt zijn van vakjes, rondjes, etc.
De OMR-applicatie weet waar juist op het
document ze moet kijken naar bepaalde gegevens. Dit heeft voor gevolg dat zelfs een lichte verschuiving van het document bij
scanning interpretatie moeilijk, zoniet onmogelijk maakt.
Maar zelfs zonder verschuiving is dit interpreteren
van aankruisvakjes niet zo eenvoudig als het lijkt. In de eerste plaats moet er een goed contrast zijn tussen het vakje dat
moet ingevuld worden en het teken dat eringezet werd. Hoe lager het contrast, hoe meer kans op fouten.
Daarnaast zal de ene persoon een groot
kruis zetten als hij iets wil bevestigen, de ander een klein vinkje, de ene mens schrijft duidelijk, de andere drukt nauwelijks
op zijn pen en schrijft heel licht, nog anderen “tikken” gewoon even het juiste vakje aan zodat hier enkel een
klein streepje in staat, nog iemand anders maakt het ganse vakje zwart wanneer
hij dit wil annuleren omdat hij van gedacht is veranderd. Ook zal niet iedereen juist in het vakje blijven. Een vinkje kan
ook te groot zijn en aan weerskanten van het in te vullen cirkeltje vallen, zodat er op de echte “leesplaats”
niets te zien is. Kortom : interpretatie is niet eenvoudig. Een mens ziet dit dadelijk, een computer heeft het hier niet zo
gemakkelijk mee. Ondanks al deze problemen werkt deze techniek over het algemeen goed.
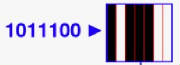
BARCODES
PRINCIPE
“Streepjescode” of “barcode” is de benaming voor een
opeenvolging van dikkere en smallere lijnen die een code vormen voor een bepaalde informatie. Een streepje heeft een vastgestelde
breedte en door bv de breedte te “meten” van streepjes en blancozones kan men zonder probleem de code ontcijferen.
Een zwarte zone staat dan bijvoorbeeld voor 1, een blanco zone voor 0. Op die manier kan dus een gans bitpatroon worden opgeslagen.
Maar er bestaan nog andere methoden
(of standaarden) om gegevens in een barcode op te slaan. Streepjes-codes worden tegenwoordig immers voor verschillende toepassingen
gebruikt, en zoals steeds gaf dit aanleiding tot verschillende “formaten” (Interleaved 2 of 5, Code 39, Code 128
A, B, of C). Deze behelzen o.a. welke opeenvolging van bits (zwartingen) een bepaald cijfer vormen (men wil nooit 4 zwarte
blokjes na elkaar kunnen krijgen bv), de start- en stop-markers (welke code geeft het begin en welke het einde aan van de
barcode), het berekenen van het controlegetal (de “checksum”) en de blanco zone die vereist is voor de eigenlijke
gegevens in de barcode beginnen.
Barcodes worden gelezen via een laserstraal
die éénmaal of verscheidene keren de barcode aftast. Wit weerkaatst de barcode meer dan zwart, dat eerder absorberend optreedt.
Een lichtgevoelige cel kan dan de opeenvolging van weerkaatsing en uitdoving van de straal opvangen. Daarna wordt de “lezing”
doorgegeven aan een programma dat deze code ontcijfert. Volgende stadium is het doorgeven naar software die de gegevens verder
interpreteert (welke inhoud, welke betekenis, welke zones van een DB worden opgevuld met welke gegevens ?)
Het spreekt vanzelf dat er minimale eisen
opgelegd worden opdat een barcode correct leesbaar zou zijn : de lijnen mogen niet te dun of te kort zijn, ze mogen niet te
dicht op elkaar staan, het verschil tussen een breed en een smal lijntje moet voldoende duidelijk zijn, er moet voldoende
zwarting zijn en het papier zelf moet voldoende weerkaatsen.

Inhoudstafel
Vorige pagina : Belangrijke Formaten
Volgende pagina : Practische Problemen
|


